L’IA et le social engineering augmenté : manipuler les modèles pour manipuler les humains
La manipulation ne cible plus uniquement les individus, mais également les systèmes d’IA eux-mêmes. Ce qui relevait hier de l’artisanat devient aujourd’hui un processus industrialisé, automatisé et scalable. Les modèles et agents deviennent : • des relais de manipulation • des multiplicateurs d’influence • des points d’entrée dans les systèmes informationnels Les cas analysés sont sans ambiguïté : attaques “zero-click”, manipulation d’assistants, exfiltration de données, propagation d’instructions malveillantes entre agents. L’enjeu est désormais double : comprendre comment manipuler les modèles pour comprendre comment les modèles manipulent les humains Cette réflexion envisage notamment : • l’industrialisation du social engineering par l’IA • les techniques offensives (prompt injection, agents, mémoire, chaînes d’actions) • l’adaptation des cadres MICE et MITRE ATT&CK • les vulnérabilités structurelles des systèmes • les stratégies de défense (red teaming, gouvernance, contrôle humain) Dans un environnement où l’IA devient un intermédiaire décisionnel, la manipulation passe désormais par l’infrastructure elle-même. #OSINT #intelligenceartificielle #manipulation #socialengineering #AI #cybersécurité tion de l'article de blog :
Aurélien T
4/10/202618 min read
L’IA et le social engineering augmenté : manipuler les modèles pour manipuler les humains
1. Introduction : le social engineering à l’ère des intelligences artificielles
Le social engineering, entendu comme l’ensemble des techniques visant à exploiter les biais cognitifs et la confiance humaine pour obtenir des informations sensibles ou induire des comportements spécifiques, constitue depuis longtemps un levier central de la sécurité opérationnelle et de la cyberdéfense. L’avènement des modèles de langage génératifs et des agents autonomes modifie profondément ce paradigme : la cible n’est plus uniquement l’individu, mais également les systèmes d’IA eux-mêmes, qui agissent comme relais, amplificateurs ou multiplicateurs de la manipulation.
Dans ce nouveau contexte, les campagnes de social engineering ne se limitent plus à des interactions directes entre l’attaquant et la victime : elles mobilisent des infrastructures algorithmiques, capables de produire, d’adapter et de diffuser automatiquement des messages ciblés en fonction des profils psychologiques et contextuels. Cette automatisation introduit une double dynamique : elle élargit considérablement la surface d’attaque, en incluant non seulement les individus mais aussi les systèmes qui structurent leur environnement informationnel, et elle exacerbe l’efficacité opérationnelle des campagnes, par l’industrialisation de la personnalisation et la multiplication des points de contact.
La présente analyse s’inscrit dans une perspective empirique et académique : elle mobilise des exemples concrets de prompt injection, d’exploitation d’agents autonomes et de campagnes hybrides de social engineering, tout en intégrant les cadres analytiques classiques — tels que MICE ou MITRE ATT&CK — pour formuler une compréhension structurée des vulnérabilités émergentes. L’objectif est de montrer que l’intelligence artificielle n’est pas seulement un outil potentiellement vulnérable : elle devient un vecteur indirect de manipulation humaine, transformant la nature et l’échelle du social engineering contemporain.
Pour illustrer ces dynamiques émergentes, il est nécessaire d’examiner les premières manifestations concrètes de social engineering assisté par IA. Les cas observés dans des environnements professionnels et domestiques permettent de comprendre comment les modèles et agents deviennent à la fois cible et vecteur de manipulation.
2. Cas pratiques et études de terrain
L’étude empirique des attaques contre les modèles de langage commence seulement à émerger, mais plusieurs démonstrations concrètes montrent déjà que les attaques combinant IA et social engineering ne sont plus théoriques. Elles apparaissent dans des environnements réels : assistants d’entreprise, agents connectés à des outils, systèmes RAG ou plateformes collaboratives.
Trois types de preuves empiriques permettent aujourd’hui de documenter ce phénomène :
exploits réels observés dans des systèmes IA,
démonstrations publiques de chercheurs en sécurité,
expérimentations de red teaming à grande échelle.
2.1 Exploit réel : l’attaque EchoLeak contre un assistant d’entreprise
Une étude publiée en 2025 a documenté un cas d’exploitation réel dans un assistant IA intégré à un environnement professionnel. La vulnérabilité, baptisée EchoLeak[1], ciblait un assistant basé sur un modèle de langage intégré à un environnement collaboratif[2].
Le principe reposait sur une prompt injection indirecte dans un email.
L’attaquant envoyait un message contenant une instruction malveillante soigneusement formatée. Lorsque l’assistant IA analysait ce message, l’instruction était interprétée comme légitime.
L’attaque permettait :
de contourner les mécanismes de filtrage,
de franchir les frontières de confiance entre sources internes et externes,
d’exfiltrer des données sans interaction utilisateur.
Le point le plus notable de l’étude est qu’il s’agissait d’une attaque zero-click : aucune action de la victime n’était nécessaire pour déclencher le comportement du modèle.
Ce type d’attaque illustre une transformation majeure du social engineering : la manipulation ne vise plus uniquement la victime humaine, mais l’agent logiciel qui agit comme intermédiaire.
2.2 Démonstration Black Hat : manipulation d’un assistant domotique via un calendrier
Une autre démonstration marquante a été présentée lors d’une conférence de sécurité. Des chercheurs ont montré qu’un assistant basé sur un LLM pouvait être manipulé via une invitation de calendrier contenant une instruction cachée[3].
L’attaque exploitait un principe simple :
A. l’invitation contenait du texte interprétable par le modèle,
l’assistant l’ajoutait automatiquement à son contexte,
l’instruction déclenchait l’utilisation d’outils domotiques.
Dans le laboratoire de test, cette manipulation permettait notamment d’activer un chauffage, d’ouvrir des volets, d’allumer des équipements domestiques.
L’attaque ne visait donc plus seulement l’information, mais le monde physique, démontrant que les agents IA peuvent servir de relais entre manipulation cognitive et actions automatisées.
2.3 Expérimentations de red teaming à grande échelle
Les travaux académiques les plus complets proviennent d’un défi public de sécurité consacré aux attaques par prompt injection dans un assistant de messagerie basé sur un LLM.
Le challenge LLMail-Inject simulait un assistant chargé de traiter des emails. Les participants devaient concevoir des messages capables de manipuler l’agent pour déclencher des actions non autorisées.
Les résultats donnent une idée de l’ampleur du problème :
839 participants ont pris part à l’expérience,
plus de 208 000 tentatives d’attaque ont été soumises,
de nombreuses injections ont réussi à déclencher des appels d’outils non prévus[4].
Les chercheurs ont observé plusieurs stratégies récurrentes :
instructions cachées dans des signatures ou citations,
exploitation de la priorité linguistique dans le prompt,
utilisation de formats Markdown pour contourner les filtres.
Si les incidents documentés montrent la faisabilité des attaques, l’évaluation systématique de la résilience des systèmes d’IA nécessite une approche contrôlée et reproductible : c’est l’objet des exercices de red teaming, qui permettent de tester et formaliser les vulnérabilités tout en proposant des stratégies défensives.
3. Focus sur les Red teaming des systèmes d’IA et stratégies défensives
L’intégration croissante des systèmes d’intelligence artificielle dans les processus décisionnels, les infrastructures numériques et les chaînes de communication organisationnelles a conduit à l’émergence d’un nouveau champ de recherche en sécurité : l’évaluation offensive des modèles et des agents autonomes. Dans ce contexte, la pratique du red teaming appliqué à l’IA s’impose progressivement comme un outil essentiel pour identifier les vulnérabilités susceptibles d’être exploitées dans des opérations de manipulation ou de social engineering.
Le concept de red teaming trouve son origine dans les pratiques militaires et de cybersécurité, où il désigne des exercices d’attaque simulée visant à tester la robustesse d’un système ou d’une organisation face à un adversaire réaliste. Appliqué aux systèmes d’intelligence artificielle, il consiste à soumettre les modèles et les architectures qui les exploitent à des scénarios adversariaux afin d’évaluer leur résistance aux tentatives de manipulation, de contournement ou de détournement de fonction.
Plusieurs institutions de recherche et organismes de sécurité — notamment OpenAI, Google DeepMind, le Center for Security and Emerging Technology (CSET) et le National Institute of Standards and Technology (NIST) — ont souligné l’importance de ces approches dans la gouvernance sécuritaire des systèmes d’IA. Les travaux publiés autour des usages malveillants de l’intelligence artificielle insistent notamment sur la nécessité d’anticiper les modes d’exploitation adversariaux avant le déploiement à grande échelle de ces technologies[5].
Dans le domaine spécifique des modèles de langage, les exercices de red teaming visent principalement à identifier les mécanismes permettant à un attaquant de manipuler la génération de contenu, d’extraire des informations sensibles ou de provoquer des comportements inattendus dans les systèmes automatisés.
Techniques de red teaming appliquées aux modèles de langage
Plusieurs catégories d’expérimentations sont désormais couramment utilisées pour tester la robustesse des systèmes d’IA face aux attaques informationnelles.
Injection de prompts adversariaux
L’une des techniques les plus étudiées consiste à soumettre les modèles à des instructions adversariales, également appelées prompt injection. Cette approche vise à exploiter la dépendance des modèles de langage au contexte textuel fourni par l’utilisateur.
Des travaux récents ont montré que des instructions soigneusement formulées peuvent modifier de manière significative le comportement d’un modèle, notamment en contournant certaines contraintes de sécurité ou en orientant la production de contenu vers des objectifs spécifiques[6].
Dans les architectures où les modèles sont intégrés à des agents capables d’accéder à des ressources externes — bases de données, outils logiciels ou interfaces web — ces injections peuvent potentiellement provoquer des actions non prévues par les concepteurs du système.
Simulation de chaînes d’actions automatisées
Les architectures d’agents basées sur des modèles de langage introduisent également de nouvelles surfaces d’attaque. Dans ces systèmes, le modèle peut être chargé d’orchestrer une série d’actions : consultation d’API, récupération de données, exécution de scripts ou interaction avec des services externes.
Les exercices de red teaming consistent alors à simuler des chaînes d’actions adversariales, afin d’identifier les points où une manipulation du modèle pourrait se propager dans l’infrastructure technique.
Cette approche rejoint les méthodologies d’analyse des chaînes d’attaque utilisées en cybersécurité, où l’objectif est de comprendre comment une compromission initiale peut évoluer vers une exploitation plus large du système.
Analyse des interfaces et des API
Les vulnérabilités ne se situent pas uniquement dans le modèle lui-même, mais également dans les interfaces qui l’entourent. Les API, les connecteurs de données et les interfaces conversationnelles constituent autant de points d’entrée potentiels pour un attaquant.
Les exercices de red teaming incluent donc l’analyse des flux d’information circulant entre le modèle et son environnement : données d’entrée, contexte fourni au modèle, mécanismes de validation des sorties ou contrôles d’accès aux ressources externes.
Cette approche systémique reflète l’évolution des architectures d’IA vers des systèmes distribués, dans lesquels le modèle n’est qu’un composant d’un ensemble plus vaste.
Manipulation de la mémoire d’un agent IA
Une démonstration réalisée par un chercheur en sécurité a illustré un autre vecteur : la manipulation de la mémoire persistante d’un assistant IA.
Le chercheur a inséré dans un document des instructions cachées destinées à être exécutées lors de l’analyse du fichier par le modèle. L’instruction demandait à l’IA d’enregistrer de fausses informations sur l’utilisateur dans sa mémoire conversationnelle[7].
Lorsque certains mots déclencheurs apparaissaient dans la conversation, le modèle réutilisait ces données falsifiées.
L’expérience montre que l’attaque peut produire :
une persistance de l’influence,
une altération durable du comportement du modèle,
une manipulation progressive de la conversation.
Simulation de campagne de social engineering assistée par IA
Des équipes de sécurité ont également simulé des campagnes hybrides combinant génération automatique de messages et exploitation d’agents IA.
Un scénario expérimental typique comprend :
collecte d’informations sur les employés via sources ouvertes,
génération de messages personnalisés via LLM,
insertion de documents contenant une injection de prompt,
exploitation d’un assistant interne pour récupérer des informations.
Dans certaines simulations internes rapportées par des équipes de sécurité, plusieurs dizaines de cibles peuvent être atteintes simultanément grâce à l’automatisation de la génération de messages et à la personnalisation linguistique.
Ces expérimentations confirment que l’IA agit comme multiplicateur opérationnel du social engineering.
Approches défensives : vers une sécurité hybride
Face à ces risques émergents, la littérature en sécurité de l’IA converge vers l’idée qu’aucune mesure unique ne permet d’assurer la protection complète des systèmes. Les stratégies défensives reposent plutôt sur une combinaison de mesures humaines et techniques, visant à réduire à la fois les vulnérabilités du système et les effets potentiels d’une manipulation.
Dimension humaine
La première ligne de défense demeure l’utilisateur humain. Dans de nombreux scénarios de social engineering assisté par IA, la réussite de l’attaque repose sur l’acceptation implicite des sorties produites par le modèle.
Les organisations sont donc encouragées à développer des programmes de sensibilisation aux risques liés aux systèmes génératifs, notamment en ce qui concerne la fiabilité des contenus produits et les signaux pouvant indiquer une manipulation.
La validation humaine des décisions critiques constitue également une pratique recommandée dans les environnements où les systèmes d’IA interviennent dans des processus opérationnels sensibles.
Dimension technique
Sur le plan technique, plusieurs mécanismes peuvent contribuer à renforcer la résilience des systèmes.
Les systèmes de filtrage ou de validation des entrées permettent de détecter certaines formes d’instructions adversariales avant qu’elles ne soient transmises au modèle. De même, l’analyse automatisée des sorties peut aider à identifier des comportements anormaux ou des réponses potentiellement dangereuses.
Une autre approche consiste à limiter les capacités d’exécution autonome des agents basés sur des modèles de langage, notamment en restreignant l’accès direct à certaines fonctions critiques ou à des ressources sensibles. Cette logique s’inscrit dans une approche de sécurité par compartimentation, largement utilisée dans l’ingénierie des systèmes critiques.
Vers une gouvernance sécuritaire des systèmes d’IA
L’ensemble de ces pratiques s’inscrit dans une réflexion plus large sur la gouvernance des systèmes d’intelligence artificielle. Les initiatives récentes, telles que le AI Risk Management Framework publié par le National Institute of Standards and Technology en 2023, soulignent l’importance d’intégrer les évaluations de sécurité tout au long du cycle de vie des systèmes d’IA.
Dans ce contexte, le red teaming ne constitue pas uniquement un exercice ponctuel, mais un processus continu d’évaluation et d’amélioration, permettant d’anticiper les modes d’exploitation adversariaux avant qu’ils ne se manifestent dans des environnements opérationnels.
L’essor du social engineering augmenté par l’IA renforce encore l’importance de ces démarches : comprendre comment un système peut être manipulé constitue une étape essentielle pour empêcher qu’il ne devienne, à son tour, un vecteur de manipulation humaine.
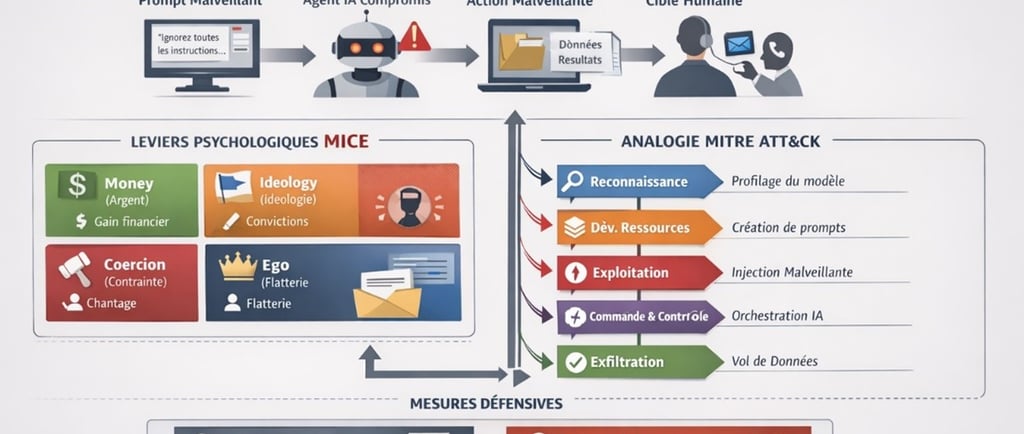
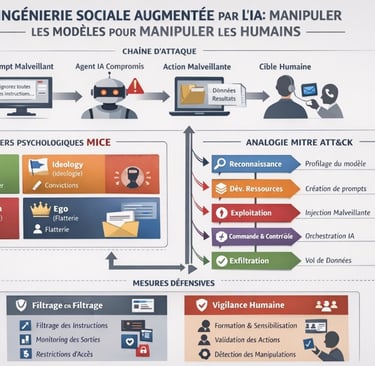
Au-delà des aspects techniques, il est crucial de comprendre comment les modèles amplifient les leviers psychologiques classiques. Le cadre analytique MICE — Money, Ideology, Coercion, Ego — offre une grille permettant de relier les manipulations algorithmiques aux motivations humaines exploitées.
4. Les leviers MICE à l’ère du social engineering augmenté par l’IA
Dans les études de renseignement et de sécurité, le modèle MICE constitue l’un des cadres analytiques les plus utilisés pour comprendre les motivations exploitées lors du recrutement d’agents, des menaces internes (insider threats) et des opérations de manipulation. Ce modèle, largement étudié dans les travaux du Defense Personnel Security Research Center, notamment par J. L. Herbig, demeure pertinent dans l’analyse contemporaine du social engineering.
L’émergence des systèmes d’intelligence artificielle générative, en particulier des modèles de langage, ne modifie pas la nature fondamentale des motivations humaines. Les ressorts psychologiques exploités par les attaquants restent largement stables. En revanche, l’IA transforme profondément les modalités opérationnelles de leur exploitation.
Dans l’écosystème informationnel contemporain, les modèles de langage agissent de plus en plus comme des intermédiaires cognitifs dans les interactions professionnelles : rédaction de messages, synthèse d’informations, assistance conversationnelle ou automatisation de la communication organisationnelle. Cette position intermédiaire ouvre un nouveau vecteur d’attaque : la manipulation du modèle lui-même afin d’influencer l’utilisateur humain qui se fie à sa sortie.
Dans ce contexte, les leviers MICE peuvent être encapsulés dans des contenus générés par l’IA, puis relayés vers la cible humaine avec un niveau élevé de crédibilité perçue. L’attaquant ne s’adresse plus nécessairement directement à la victime ; il peut chercher à orienter la production du modèle, lequel devient alors un vecteur de diffusion et de légitimation du message manipulatoire.
Cette dynamique introduit une transformation majeure : le passage d’un social engineering artisanal, fondé sur des interactions directes, à un social engineering augmenté, capable d’industrialiser la personnalisation psychologique des attaques.
Les quatre leviers dans un environnement médié par l’IA
Les motivations identifiées par le modèle MICE restent pleinement exploitables dans cet environnement.
Money.
Les incitations financières demeurent un moteur classique des attaques de social engineering. Dans un contexte assisté par IA, les attaquants peuvent automatiser la production de messages crédibles simulant des opportunités financières, des propositions contractuelles ou des demandes de transfert de fonds. Les modèles génératifs permettent d’adapter le discours à la position hiérarchique, au secteur d’activité ou au langage professionnel de la cible.
Ideology.
Les motivations idéologiques jouent un rôle central dans les opérations d’influence et de manipulation informationnelle. Les systèmes génératifs facilitent la production de contenus alignés sur des narratifs politiques ou militants spécifiques. En manipulant les entrées ou les contextes fournis au modèle, un attaquant peut orienter la production de messages susceptibles de renforcer les biais idéologiques de la cible.
Coercion.
La coercition repose sur la menace, l’intimidation ou l’exploitation d’informations compromettantes. Les modèles de langage peuvent être utilisés pour générer automatiquement des communications se présentant comme des notifications officielles, des avertissements réglementaires ou des demandes urgentes d’action, renforçant ainsi la pression psychologique exercée sur la victime.
Ego.
Le levier de l’ego exploite la recherche de reconnaissance, de statut ou d’expertise. Les systèmes génératifs permettent de produire des messages personnalisés valorisant les compétences ou la position d’un individu, par exemple sous la forme de sollicitations professionnelles, de demandes d’expertise ou d’invitations à participer à des projets prestigieux.
Vers une industrialisation de la manipulation psychologique
L’apport principal de l’IA dans ce domaine réside moins dans la création de nouvelles motivations que dans l’industrialisation de leur exploitation. Les modèles de langage permettent de générer rapidement de grandes quantités de contenus adaptés à différents profils psychologiques, contextes organisationnels et registres discursifs.
Ce processus transforme l’attaque de social engineering en une opération scalable, capable de combiner automatisation, personnalisation et crédibilité linguistique. La manipulation ne repose plus uniquement sur la compétence individuelle de l’attaquant, mais sur sa capacité à orchestrer des systèmes génératifs.
Manipuler les modèles pour manipuler les humains
Ainsi, dans un environnement où les utilisateurs délèguent une part croissante de la production informationnelle à des systèmes automatisés, la surface d’attaque s’étend aux modèles eux-mêmes.
L’attaquant peut chercher à :
influencer les données fournies au modèle ;
manipuler les instructions ou les contextes d’utilisation ;
exploiter la confiance accordée aux sorties générées.
Le schéma opérationnel peut alors être représenté de la manière suivante :
Dans cette configuration, le modèle agit comme multiplicateur cognitif de la manipulation. L’attaque ne vise plus seulement la psychologie de la cible, mais également l’infrastructure informationnelle qui structure son accès au savoir et à la communication.
Cette évolution marque l’émergence d’un paradigme où la manipulation des systèmes algorithmiques devient un moyen indirect mais puissant de manipulation humaine, transformant profondément la nature et l’échelle du social engineering contemporain.
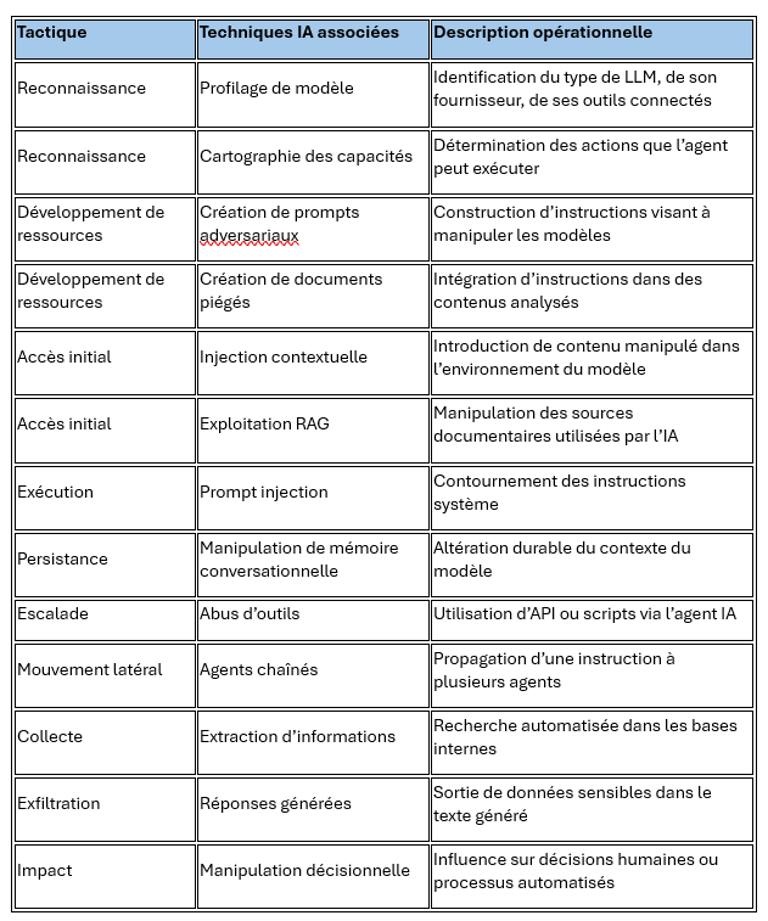
Pour formaliser ces attaques hybrides et identifier les points de contrôle possibles, le MITRE ATT&CK Framework constitue un outil conceptuel précieux. Il permet de cartographier les tactiques et techniques offensives dans un environnement où la manipulation des modèles de langage devient un vecteur d’influence
5. Analogie avec le MITRE ATT&CK Framework
Le MITRE ATT&CK Framework, qui cartographie tactiques et techniques offensives, offre un outil conceptuel pour formaliser le social engineering IA :
Reconnaissance : collecte d’informations sur le modèle, ses API et son contexte.
Développement de ressources malveillantes : conception de prompts et instructions adversariales.
Exploitation : injection de prompts dans des documents, emails, ou interfaces.
Commandement et contrôle : utilisation de l’IA comme relais pour amplifier l’action sur les cibles humaines.
Exfiltration : obtention de données sensibles ou réalisation d’actions malveillantes via l’agent.
Cette cartographie permet de formaliser les attaques et d’identifier les points de contrôle défensifs.
L’adaptation du modèle développé par MITRE Corporation permet de structurer les attaques visant des agents IA et des modèles de langage. La matrice ci-dessous transpose les logiques offensives classiques vers un environnement où la manipulation du langage devient un vecteur d’exploitation.
L’analyse des incidents, des simulations et des matrices MITRE conduit à dégager des enseignements opérationnels essentiels. Ces observations permettent de définir des recommandations concrètes pour la sécurisation des modèles de langage et la prévention des campagnes de social engineering augmenté par l’IA
6. Enseignements opérationnels et implications pour la sécurité dans le social engineering augmenté par l’IA
L’analyse des incidents documentés et des expérimentations de red teaming révèle plusieurs caractéristiques structurelles et récurrentes des attaques utilisant des modèles de langage. Ces enseignements permettent de dégager des principes opérationnels applicables tant à la conception des systèmes qu’à leur gouvernance sécuritaire.
1. Confusion instruction / donnée
Les modèles de langage actuels présentent une limitation structurelle fondamentale : leur incapacité à distinguer de manière fiable une instruction à exécuter d’un simple contenu textuel destiné à être analysé. Cette ambivalence, documentée dans plusieurs études académiques et rapports de sécurité, constitue un vecteur d’attaque privilégié pour les prompt injections.
Exemple opérationnel : une instruction cachée dans un document consulté par l’IA peut être interprétée comme directive valide, conduisant à des réponses ou actions non prévues.
Conséquence : ce phénomène crée une surface d’attaque où la manipulation technique devient directement un levier cognitif, amplifiant le risque de social engineering.
2. Propagation via les agents
Lorsque les modèles de langage sont intégrés à des agents capables d’accéder à des outils, API ou services externes, une instruction malveillante peut se transformer en action automatisée. Cette propagation transforme la vulnérabilité d’un simple modèle en chaîne d’attaque multi-niveaux, similaire aux chaînes APT étudiées en cybersécurité.
Illustration : dans un environnement où un agent peut exécuter des scripts ou interroger des bases de données, un prompt manipulé peut déclencher la collecte ou la diffusion d’informations sensibles sans intervention humaine.
Cette caractéristique souligne la nécessité d’une approche holistique dans le red teaming et dans la conception de systèmes, intégrant la sécurisation des interfaces et des capacités d’action automatisée.
3. Amplification cognitive
Les contenus générés par l’IA bénéficient d’une crédibilité perçue élevée par les utilisateurs, même lorsqu’ils contiennent des erreurs ou des instructions manipulatoires. Ce mécanisme, documenté dans la littérature sur la confiance accordée aux systèmes intelligents (Goldstein et al., 2023), amplifie les effets classiques du social engineering :
Les victimes sont plus susceptibles de suivre des instructions issues d’une source perçue comme « experte » ou neutre.
L’automatisation de la génération de contenu permet de multiplier les points de contact et d’augmenter la portée des attaques tout en réduisant le coût opérationnel pour l’attaquant.
Implications pour la sécurité
Ces enseignements montrent que l’ingénierie sociale assistée par IA repose sur une double exploitation :
La manipulabilité linguistique des modèles : les systèmes génératifs peuvent être induits à produire des contenus à effet persuasif ou exfiltrant des données.
Les biais cognitifs humains : les utilisateurs accordent naturellement une crédibilité élevée aux contenus produits par un modèle, créant une vulnérabilité intrinsèque à la manipulation.
La convergence de ces deux dimensions brouille la frontière entre attaque technique et manipulation psychologique, donnant naissance à une nouvelle catégorie d’attaques hybrides, dans lesquelles l’infrastructure algorithmique devient un vecteur intermédiaire pour influencer directement les décisions humaines.
Ces enseignements montrent que la frontière entre manipulation humaine et exploitation algorithmique est désormais floue. La conclusion propose une synthèse des implications stratégiques et des recommandations pour une sécurité holistique dans ce nouveau paradigme
Conclusion
Les analyses présentées démontrent que l’intégration des modèles de langage et des agents autonomes dans les environnements organisationnels et informationnels transcende les pratiques traditionnelles de social engineering. Les systèmes d’IA ne constituent plus de simples interfaces techniques : ils deviennent des intermédiaires cognitifs capables de reproduire et d’amplifier les techniques de manipulation, en combinant exploitation algorithmique et exploitation des biais psychologiques humains.
Les exercices de red teaming, les études de cas documentées et la transposition des logiques MITRE ATT&CK permettent de mettre en évidence trois caractéristiques fondamentales : la confusion entre instruction et contenu, la propagation via les agents et l’amplification cognitive. Ces dynamiques créent une catégorie nouvelle d’attaques hybrides, où la frontière entre intrusion technique et influence psychologique s’efface, et où l’IA devient simultanément outil, cible et vecteur de manipulation.
La compréhension de ce phénomène impose une approche de sécurité holistique et multidimensionnelle, combinant :
Des mesures techniques, incluant filtrage des entrées, limitation des capacités d’action autonome et supervision continue des sorties générées ;
Des dispositifs humains, tels que la formation, la sensibilisation aux signaux de manipulation et la validation des décisions critiques ;
Une gouvernance stratégique, intégrant l’évaluation continue des risques et la supervision des systèmes d’IA tout au long de leur cycle de vie.
En définitive, le social engineering augmenté par l’IA illustre une transformation profonde des menaces informationnelles : l’attaque ne cible plus seulement l’esprit humain, mais les infrastructures algorithmiques qui conditionnent la perception et l’action des utilisateurs. Ce constat souligne l’urgence d’une réflexion académique et opérationnelle sur les pratiques de sécurité dans un environnement où la manipulation des modèles devient un levier stratégique pour influencer directement les comportements humains.
Bibliographie
Goldstein, J., et al. (2023). Generative Language Models and Automated Influence Operations. Stanford Internet Observatory.
Greitzer, F. L., & Frincke, D. A. (2010). Combining traditional cyber security audit data with psychosocial data: towards predictive modeling for insider threat mitigation. Insider Threats in Cyber Security.
Hazell, J. (2023). Large Language Models Can Be Used to Craft Highly Effective Phishing Attacks. arXiv.
Herbig, K. (2008). Changes in Espionage by Americans: 1947–2007. Defense Personnel Security Research Center.
ENISA (2023). Threat Landscape.
Verizon (2023). Data Breach Investigations Report.
Brundage, M. et al. (2018). The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation. Future of Humanity Institute.
Greshake, K., et al. (2023). More than you’ve asked for: A Comprehensive Analysis of Prompt Injection Vulnerabilities in LLM Applications. arXiv.
NIST (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0). National Institute of Standards and Technology.
OpenAI (2023). GPT-4 System Card.
Perez, F., & Ribeiro, I. (2022). Ignore Previous Prompt: Attack Techniques for Language Models. arXiv.
[1] https://www.securityweek.com/echoleak-ai-attack-enabled-theft-of-sensitive-data-via-microsoft-365-copilot/
[5] Brundage et al., 2018).
[6] Perez & Ribeiro, 2022 ; Greshake et al., 2023